Hi all...
Yes, it's been a while since I wrote the last article in this series. I apologize for that. This summer has been busy both at work and home (not like I got to go on a cruise like Ed Merks or anything, but we've been bouncing around!). So the series of articles fell by the wayside a bit.
That said... Let's get back to it. When we last left our intrepid coders, we were working through the steps of trying to get SQLite to connect and show its underlying model (schemas/tables/procedures, etc.) in the Data Source Explorer. We had just finished creating some driver templates (see that article
here) and that didn't really buy us all that much.
The next step is to then create a custom catalog loader to take care of any shortcomings of the SQLite driver. We have a db definition (vendor/version) to hang the catalog loader from, which means we just have to choose which level to focus on first.
In this case, since we're interested in schemas as the highest level of the model for SQLite, we'll override the schema catalog loader.
To do this, we need to do a things.
1) In the plug-in manifest editor (opened either from MANIFEST.MF or plugin.xml) for the org.eclipse.datatools.enablement.sqlite plug-in project, we need to add a new dependency. Select the Dependencies tab in the manifest editor and add org.eclipse.connectivity.sqm.core. This will provide one of the extension points that we need to extend to override the catalog loader.
2) On the Extensions tab, add a new extension and select org.eclipse.datatools.connectivity.sqm.core.catalog. Right-click on the extension and select "overrideLoader". Then select the "overrideLoader" node in the extension tree. You should see something like the following:
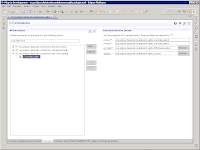
Product and version equate directly to the db definition that we've already created. Provider is the actual loader class we'll override the default with. And eclass is the SQL model class that we want to override the loader for our SQLite databases.
In this case:
* product = SQLITE
* version = 3.5.9
* eclass = org.eclipse.datatools.modelbase.sql.schema.Schema
* provider = a new class we'll create called SQLiteSchemaLoader
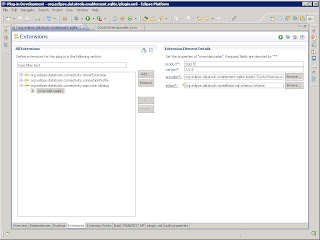
The SQLiteSchemaLoader looks something like this:
package org.eclipse.datatools.enablement.sqlite.loader;
import org.eclipse.datatools.connectivity.sqm.core.rte.ICatalogObject;
import org.eclipse.datatools.connectivity.sqm.loader.IConnectionFilterProvider;
import org.eclipse.datatools.connectivity.sqm.loader.JDBCSchemaLoader;
public class SQLiteSchemaLoader extends JDBCSchemaLoader {
public SQLiteSchemaLoader(ICatalogObject catalogObject,
IConnectionFilterProvider connectionFilterProvider) {
super(catalogObject, connectionFilterProvider);
}
}
Since SQLite has no concept of a "schema", we need to dummy one up so that the model is satisfied. (Yes, this is one more case where the loose JDBC "standard" bites us in the rear when we try to adhere to it.) To do that, we really only need to focus on overriding a couple of key methods:
* protected void initialize(Schema schema, ResultSet rs) throws SQLException
* public void loadSchemas(List containmentList, Collection existingSchemas) throws SQLException
In the default JDBCSchemaLoader, it relies on the driver to provide a result set of schemas. In the SQLite case, since there are none, we need to change the behavior to just dummy up a schema object and pass it along.
So loadSchemas becomes:
public void loadSchemas(List containmentList, Collection existingSchemas)
throws SQLException {
Schema schema = (Schema) getAndRemoveSQLObject(existingSchemas,
"DEFAULT");
if (schema == null) {
schema = processRow(null);
if (schema != null) {
containmentList.add(schema);
}
}
else {
containmentList.add(schema);
if (schema instanceof ICatalogObject) {
((ICatalogObject) schema).refresh();
}
}
}
And initialize is changed to ignore the result set and just name the schema "DEFAULT":
protected void initialize(Schema schema, ResultSet rs) throws SQLException {
schema.setName("DEFAULT");
}
The last thing we have to do is make our catalog loader class actually run as an executable extension. If we don't add the following constructor, you get an InstantiationException, which is always a pain to track down:
public SQLiteSchemaLoader() {
super(null);
}
Once the dummy schema is in place, the driver actually does return the tables list correctly, as seen in the following screen shot.

However... It appears that the SQLite driver does not return getImportedKeys() directly (it throws a "not yet implemented" SQLException for me), so we will need to clean up the JDBCTableConstraintLoader before we're done, but we can do that during code cleanup. (We'll also have to remove some of the nodes that don't make sense for a SQLite database, such as Authorization IDs, Stored Procedures and User-defined Functions.)
So now we have a (mostly) working catalog loader that will connect to a SQLite database and allow us to drill in and see tables and columns.
In the next article we'll walk through the simplified process for creating a brand new connection profile (wizard, wizard page, property page, connection factory, and connection classes). And then we can talk about the clean up phases and some of the nice things we can do to help out our users and developers.
Hope that helps!
--Fitz

![Reblog this post [with Zemanta]](https://lh3.googleusercontent.com/blogger_img_proxy/AEn0k_vIKIQQw2hYDD6a8oVMdY98LeG1_IfOD6h53iNpPLV_tgn60oDyNDVKhSVfacJDm_PcMpe_oH8R1-bvR2K3Q2p2FIZWM92F1_uGQAtAUb2gGPU36RP7UaVlS690Ki145xdKEg-wF4G8UrAy_KNphklt=s0-d)


![Reblog this post [with Zemanta]](https://lh3.googleusercontent.com/blogger_img_proxy/AEn0k_vDiGMRi866-_mhrorYg9ntf84p2DkoWo6tU9c2WU3xaV_WQfK1e-2fjxZq3w04qtyQaIOrUnAk-xyJENYfpz3SqONrlLLA3A1hg80YVG28I2pML_IKYAqtHTBaneczdwJsgDEP0tx9q_ONITC4svof=s0-d)
![Reblog this post [with Zemanta]](https://lh3.googleusercontent.com/blogger_img_proxy/AEn0k_td7VXLr_y1ZA_FlANqzIvK2FunPilMZsKDHgXqVPl3rVvKKoBOpdpP3mitawaXouwAS1WIjOX2v_dLdphJ8lDR8JPxMl_aodtx8iY7iIVgNZIb8SeKHy9NY6RW7QUe9bpifC1Yo-hQe3IhYKREdGxY=s0-d)




